
Agentic AI for National Security
A maturity matrix for for LLM-based agents in the national security community


The term AI agents has been lighting up discussions across the commercial and defense communities, fueled by both excitement and anxiety. Some leaders envision autonomous AI that could accelerate intelligence production, manage logistics seamlessly, or even analyze threats in real time—while others worry about how such agents might displace human analysts or operators. Headlines often trumpet software agents that can autonomously handle everything from supply chain tasks to mission planning, driving speculation about fully robotic military staff or AI-run intelligence cells. Colleagues in the defense community are already being asked to draft policy on Agentic AI. Can every soldier have a legion of AI agents standing with them? Yes and no.
At the core of the question, there’s a lot of confusion: What exactly does Agentic AI mean in practice? Ask five different scientists, and you’ll likely get five different answers. I polled a number of people at my company a few months ago, and we still didn’t have a consistent response, and we literally have spent years building a platform for Agentic workflows.
So, what follows is a way to breakdown the relatively maturity of Agentic AI systems—centered on large language model (LLM) capabilities—and how it’s evolving toward higher levels of autonomy. We’ll outline maturity levels from L0 to L5, which closely aligns with the way we measure automobile autonomy, highlighting the unique operational and policy considerations these levels pose for national security organizations.
But Let’s Start with a Reality Check
Two years ago (2023), generative AI burst onto the scene. Tools like ChatGPT dazzled users with human-like text creation. Many agencies began pilot efforts, hoping to streamline intelligence production or operational planning. Yet progress to true deployment has been slow:
Data Access: AI isn’t much use if it’s cut off from the classified or mission-critical data behind your firewalls. Without bridging that gap, the model reverts to giving generic, unhelpful answers.
Policy & Oversight: Clearance, chain-of-command protocols, legal guidelines—these structures aren’t easily bypassed.
Compute at Scale: The best LLMs need a lot of GPU horsepower, which isn’t always available in classified networks.
Experimental pilots such as NIPRGPT and CAMOGPT have been incredible tools to help educate the Nat Sec community, but they remain isolated from real data flows and, by extension, real missions. Bottom line: advanced AI can’t do its job if it isn’t hooked into operational systems under the right guardrails. That’s the driving reason national security stakeholders are now looking at agentic AI—a kind of smart automation that can talk to relevant systems and do more than just spit out text.
Agentic AI Maturity Levels (L0–L5)
Thinking about AI agents can be complicated, so it helps to categorize them by maturity. Just as self-driving cars move from zero autonomy (the driver does everything) to full autonomy, AI agents can be described on a spectrum of reasoning, planning, and execution capability. Below is a widely used framework for LLM-based agent maturity, from L0 (simple automations) to L5 (theoretical, human-level autonomy).
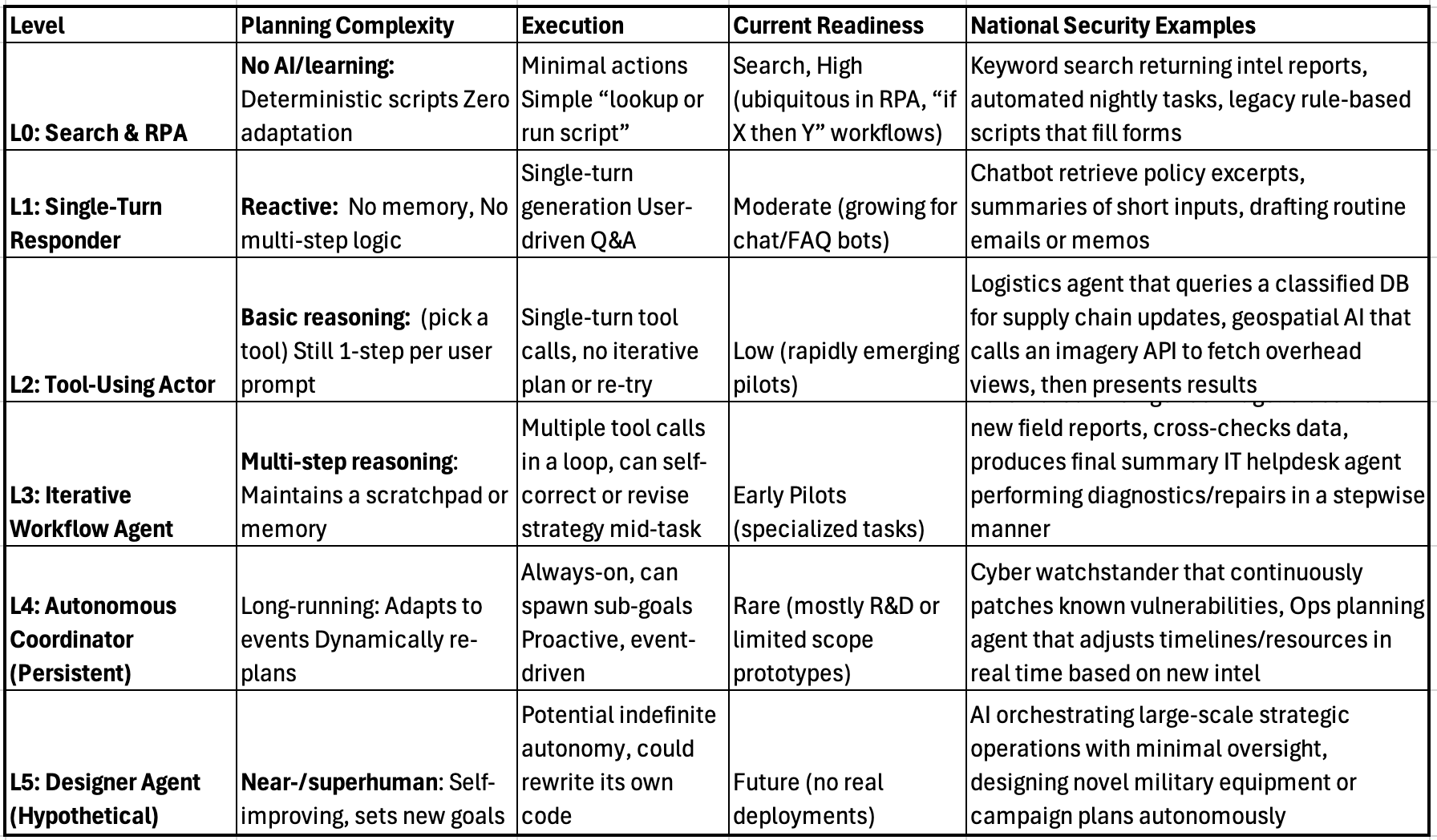
L0 – Retrieval & Rule-Based Automation (No Real AI)
Level 0 is basic retrieval (search), scripts, or RPA (robotic process automation)—no actual AI. The system follows predetermined rules (“if X, then Y”) without any learning or adaptation. The execution of these systems are deterministic. If conditions change, a human must reconfigure the script.
Examples in National Security:
Keyword-based search for intelligence reports, returning only exact matches.
Simple RPA bots that auto-fill forms in a personnel system.
A legacy workflow rule that copies data from one classified database to another every night.
While these can save man-hours for rote tasks, they lack the ability to handle variance, interpret new patterns, or autonomously correct errors. They remain the dominant form of automation in many government agencies—familiar but inflexible. However, it’s important to note that basic L0 tools can still have a profound effect on the Department of Defense. Personnel constantly rotate into new positions, situation reports (SITREPS) or after action reports (AARs) are often buried in email boxes, sharepoint sites, and folders of people that have long moved on to other jobs.
L1 – Assisted Intelligence (Basic Responder)
A Level 1 agent incorporates some AI—often a single-turn LLM chat assistant or basic machine learning classifier—but only reacts to prompts or inputs. It has no persistent memory or multi-step planning.
Examples in National Security:
An FAQ-style chatbot that, when asked about a policy or regulation, looks up a relevant document and provides a quick excerpt.
Email drafting assistants that propose text for standard communication (like official memos) but rely on the human to finalize or send.
They’re simple to deploy and can improve productivity (e.g., drafting intelligence summaries faster). No autonomy or memory of previous interactions—still heavily human-driven.
Most basic intelligence analysis or policy drafting tools powered by an LLM fall into L1.
L2 – Tool-Using Agent (Actor)
For the U.S. Department of Defense (DoD), the Intelligence Community (IC), and allied agencies, the imperative is clear: Let AI see and act on relevant data. Tools, in this context, are application programming interfaces (APIs) or connectors that equip an LLM-based agent with capabilities to read or update databases, run analytics, or engage with specialized software. By adding tool access, an agent transitions from a mere text generator to an operator that can: query systems then propose orders or automate routine work.
For example, it might see a request for “current satellite imagery for region X” and decide, “I need to call the satellite-imagery API.” After obtaining the data, it incorporates the result into its final response.
L2 has limited but improved reasoning and planning capabilities. The agent decides which tool to use but typically only in a single-turn flow (no multi-step adaptation). It can fetch or update data in real-time, but once it gives the user an answer, it resets.
Examples in National Security:
A logistics query agent that taps into a supply-chain database to confirm inventory or shipping times.
An analytics chatbot that calls a geospatial API to retrieve overhead imagery or relevant open-source data, then summarizes it.
Tool-using AI can do more than answer general questions—it can provide timely, context-specific outputs. This is crucial for, say, real-time intelligence or mission data. However, L2 agents don’t iterate or self-correct if the initial tool call fails—they wait for a human to re-prompt.
We already see frameworks enabling this at varying levels of classification. For instance, OpenAI added function calling so GPT-4 can invoke external APIs, Anthropic introduced the Model Context Protocol (MCP) to streamline hooking up its Claude model with a wide range of enterprise or government data sources. Microsoft has integrated GPT-4 into Office 365 Copilot for drafting documents or scanning emails, with an eye toward controlled enterprise (and potentially government) deployments.
In the national security sphere, these integrations must be very carefully governed (e.g., controlling which data the AI sees, auditing agent actions). Nonetheless, the principle is the same: agents gain real power to assist or automate tasks when they can access systems and data—within established security protocols.
L3 – Autonomous Workflow Agent (Operator)
Level 3 agents manage entire multi-step tasks autonomously. They maintain a “working memory” that tracks sub-tasks and partial results, and they iteratively plan actions until they meet a specified goal.
Reasoning & Planning: Robust. The agent breaks down a mission or objective, calls tools in a sequence, and adjusts if a step goes wrong.
Execution: Repeated cycles of “plan → decide → act → observe” until the agent either completes the goal or hits a failure condition.
Examples in National Security:
An IT helpdesk agent that detects a server outage, runs diagnostics, attempts known fixes, and escalates to a human if not resolved—all without needing repeated prompts.
A personnel security (PERSEC) agent that, when given a list of new hires, automatically checks relevant clearance status, schedules briefings, creates system logins, and logs all steps in a compliance system.
An intelligence triage agent that can read incoming field reports, classify them by priority, gather context from a known database, and produce summarized bulletins for analysts.
At L3, an agent can handle tasks that previously required an entire human-run workflow. This is “closed-loop autonomy” for a bounded mission scenario—greatly reducing overhead. However, it’s not continuous or always on, and it usually ends once the assigned workflow completes. Additionally, these systems can still get stuck or produce errors, so a human oversight mechanism is common (e.g., final approval of a summary).
L4 – Fully Autonomous Agent (Explorer)
This agent runs persistently—monitoring the environment, initiating tasks on its own, and adapting strategies over time. Think of it as an always-on digital staff officer that doesn’t wait for a user to say “go.” This is advanced AI (doesn’t really exist yet). It maintains a dynamic plan, re-prioritizes based on new information, can generate sub-goals without explicit prompts. It sees triggers or data changes, updates its approach, and only involves humans if necessary or mandated by policy.
Examples in National Security:
A cyber defense watchstander that constantly monitors network traffic, detects anomalies, and takes mitigative action (e.g., quarantining a compromised server), escalating to a human only when encountering something it hasn’t seen before.
A persistent ops planning agent that monitors intel updates, modifies operational timelines, reassigns resources automatically, and flags big changes to human planners.
While Level 4 has huge potential for 24/7 coverage and rapid response, it also introduces major policy and oversight questions. Agencies must specify what an autonomous agent is allowed to do—especially in sensitive missions. Currently, truly robust L4 deployments remain rare, mostly in pilot programs or strictly limited to non-critical tasks.
L5 – Designer Agent (Inventor)
This is the hypothetical end-state: an AI with near-human or superhuman adaptability, able to set its own objectives, invent new solutions, and potentially rewrite its own code to improve. It can address open-ended missions with minimal human input. Expert-level of reasoning or beyond. Capable of original strategies, extensive self-improvement, and operating across domains. The agent can conceive, plan, and execute missions that even humans hadn’t foreseen.
True L5 autonomy remains more science fiction than reality. Imagine an AI that could design entire military campaigns, develop novel equipment, or handle diplomatic negotiations without direct human oversight. No current system is anywhere near this. While defense R&D might target incremental aspects of L5 (like self-learning or creative problem-solving), we’re not close to fully unleashing an AI “commander.”
For now, L5 is more of a thought experiment—useful for glimpsing the far future of AI in defense but well beyond the horizon of current technology and policy acceptance.
Governance and Guardrails
As agencies inch toward L3 and even experiment with L4, questions of policy and oversight become paramount. Most see a phased approach: start with lower-stakes tasks, adopt robust logging at each step of the agent’s execution, and limit the scope of what the AI can do unilaterally. Many workflows will include a final “human check”—for instance, the agent can compile an intel report, but only a cleared analyst can send it to the broader community. Meanwhile, agencies drafting official Agentic AI policies often incorporate strict role-based permissions so the agent sees only the data it truly needs, mitigating the risk of unauthorized data access or misinterpretation.
From a technical standpoint, stress-testing or red-teaming the agent is critical. Researchers deliberately feed contradictory or incomplete data to ensure the system doesn’t spiral into endless loops or propose dangerous actions. These steps aren’t meant to slow innovation; they’re about ensuring that as autonomy grows, trust grows alongside it.
Where We Stand and Where We’re Going
Today, most defense and intelligence organizations are sitting at L0–L1, with pockets of pilot projects nudging into L2 or L3. Simple automations and single-turn AI assistants already help handle administrative burdens, summarizing policy docs or assisting with standard inquiries. The next leap—connecting LLMs securely to real operational systems—will likely push more teams into L2 territory. Over time, specialized tasks such as daily watch-floor data triage or repetitive maintenance checks are prime candidates for L3-level autonomy. L4 deployments may emerge in specific domains, like continuous cybersecurity monitoring, but that scale of autonomy will remain carefully controlled and tested. L5 remains an idea on the far horizon.
In the end, Agentic AI should never be about replacing human judgment in sensitive operations; it should aim to elevate human teams above rote tasks, letting them focus on analysis, strategy, and the unpredictable nature of conflict and security.
Can every soldier have a legion of AI agents standing with them? Yes. With measured implementation, thorough testing, and well-designed oversight, these AI-driven agents can act as force multipliers, improving readiness and response times. The key is to adopt them thoughtfully—aligning each level’s autonomy with mission needs, robust guardrails, and a healthy respect for the complexities of letting a machine do more than just talk.
**Some references on others ways to frame Agentic maturity:
US EPA Autonomous Vehicle Definition.
Anthropic’s Building effective agents: Workflows vs Agents.
OpenAI’s Functions vs Tools
Vellum’s similar view to L0-L5. (discovered after the draft -whomp whomp).