
GPT‑5: The big step towards a smaller future
Routing and orchestration of the fleet (or Legion) of models and agents. What It Means for the DOD, enterprise, and the future of AI.

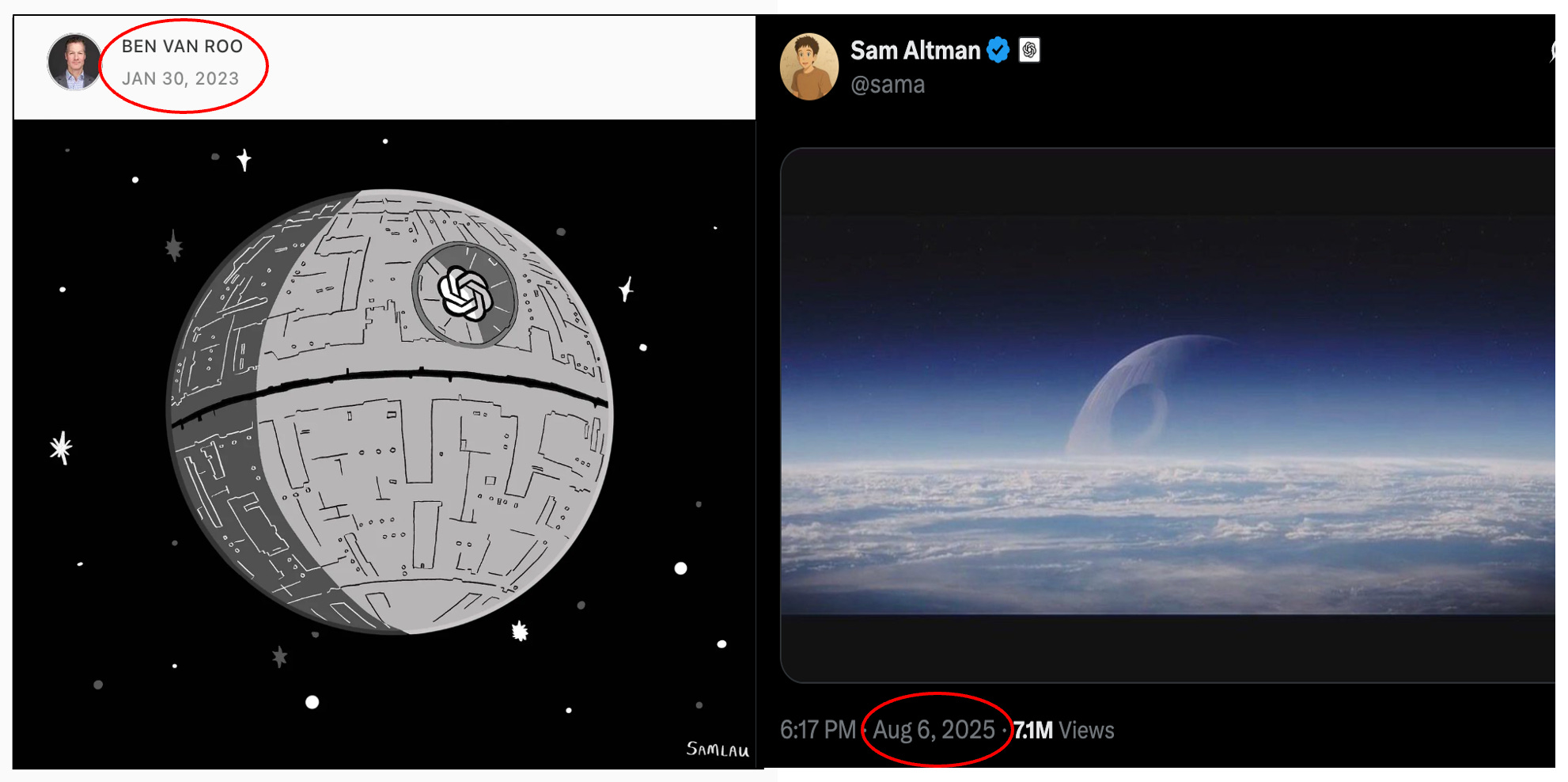
When Sam Altman posted a Death Star peeking over the horizon on X, I laughed and winced at the same time. It was a perfect callback to a piece I wrote over 2.5 years ago, arguing that GPT‑4 felt like a Death Star—vast power in a single sphere. Sam’s post about GPT-5 instead signaled that we have entered the next era: the “big model” was finally over, and the world is about to think differently about AI.
In January of 2023, I believed (and bet my company) on orchestration as the eventual winner over massive models, and my Death Star post signaled that. I then drafted but didn’t publish a piece called “He’s going Full Palpatine.” The follow-on post was a nod to Episode IX (ugh) — with fleets of Star Destroyers with fully operational Death Star killing capabilities, just in a smaller, focused form factor. Way more effective than a single massive planet killer.
GPT‑5’s launch is very important – especially since it isn’t one moon‑sized model anymore. It is routing and orchestration of models. It is a fleet, and it is traffic control. It’s a dispatcher deciding when to think hard, when to move fast, and when to call for backup.
While no one likes a chest‑thumping self-high five post on “what I got right” about pre-GPT‑4 vs. present GPT‑5. There is value in looking at the past and where we have come, and peering a bit into the future. We’re entering the era of orchestration: models, agents, and workflows. We’re accelerating, and we’ll never look back…
...but let’s take a quick look back to the pre-GPT-4 issues of January 2023:

Fewer hallucinations: the quiet but important headline
Back then, I argued we needed much better reliability and factual outputs before we could really adopt LLMs in the enterprise and national security. GPT‑5’s most important improvement might be the least sexy: it meaningfully reduces factual mistakes.
OpenAI’s system card shows two things worth translating from researcher‑speak to normal English. First, on real ChatGPT traffic, GPT‑5’s mainstream model (“gpt‑5‑main”) produced 44% fewer answers with at least one major factual error than GPT‑4o; the deeper reasoning variant (“gpt‑5‑thinking”) produced 78% fewer than OpenAI’s o3 on the same yardstick. Second, across open‑ended factuality tests like LongFact and FActScore, GPT‑5’s reasoning model shows much lower claim‑level error rates than predecessors. That’s not perfection; it is a step‑change in day‑to‑day accuracy.
For those building RAG (retrieval‑augmented generation) into real workflows, none of this is surprising: better retrieval + better abstention = fewer confabulations. Academic and field studies continue to show RAG can reduce hallucinations when the retrieval chain is engineered well, and also that poor retrieval can cause hallucinations. The work is in the plumbing, and the advancements of GPT-5 with RAG will get us even closer to operational AI that we can rely on.
Many models, one system—routing as the first face of orchestration
Another prediction from that earlier piece was that the “one giant model” narrative would give way to systems. GPT‑5 made that explicit: a unified setup with a fast default model, a deeper reasoning model, and a router that chooses between them (and smaller fallbacks as you hit usage limits). You can even ask it to “think hard” and it will change gear. That’s not a marketing flourish; it’s the product acknowledging the world’s diversity of questions and constraints.
The funny part: the auto‑router stumbled out of the gate. Within 24 hours, Sam tweeted that the autoswitcher “broke” and OpenAI temporarily restored GPT‑4o after users complained about changes in behavior. Mistake or A/B test? Early days for a complex dispatcher—but that’s the point: the router is the product now. Expect more A/Bs, not fewer.
Routing is one real manifestation of a broader orchestration layer: policy‑aware routers, retrieval that respects entitlements, tool selection, caching, cost caps, and post‑hoc verification. In other words, not just “pick a model,” but coordinate models, tools, and data to hit an SLA for accuracy, latency, and cost.
If routing is the front door. Orchestration is the house:
Intent → Plan. Classify task, risk, and required evidence.
Plan → Retrieval + Tools. Fetch only what the user can see; call tools that reduce uncertainty (search, code, db queries, sims).
Cheap first. Try the fastest model at a capped “thinking budget.” If confidence < threshold, escalate to the deeper tier.
Verify & ground. Run a small verifier against claims (and a hallucination/consistency check when needed).
Attach proof. Sources, versions, chain‑of‑custody, and a confidence rubric ship with the answer.
Log & learn. Close the loop so the router gets smarter (and cheaper) over time.
That’s orchestration. It’s also how you operationalize cost as a first‑class parameter, not an afterthought. Price cuts like GPT‑5’s make this even more compelling; they widen the surface where “cheap first, escalate when needed” pays off.
Cost: the real competitive weapon
Costs are falling fast—and GPT‑5 came in swinging. API pricing lands at $1.25/M input tokens and $10/M output for the flagship; the mini is even cheaper. That’s not a nudge; it’s a price war signal. By comparison, Anthropic’s Claude Sonnet tier is $3/M in and $15/M out (with higher prices beyond 200K context).
Zoom out, and the curve behind this is steeper than most budget spreadsheets assume. Independent analyses show inference prices falling by orders of magnitude per year at equivalent capability thresholds. Meanwhile, credible open-weight projects report single-digit million training runs (with important caveats about total program cost). Net‑net: the cost to use intelligence keeps sliding, while the cost to build it is getting more nuanced.
For buyers—and for DoD—this shifts the optimization problem from “which model?” to “what orchestration minimizes unit cost for a verified answer?”
Where this leaves us
Some people will look at GPT‑5 and shrug. That’s understandable—and probably wrong. The public launch is a snapshot; the system is what evolves. The router will improve. The “pro” variants will drift forward. OpenAI is also releasing open‑weight models under Apache 2.0, which signals a dual‑track future: closed where safety and capability demand it, open where customization and cost do. (Their model card spells out why open‑weights require extra system‑level guardrails—again, orchestration.)
All of this lands in a market where Anthropic, Google, and open‑source teams are shipping impressive work and cutting prices of their own. That’s good for users, and—if you’re the DoD—good for competition and resilience.
When I called GPT‑4 a Death Star, the industry still felt like it was building singular weapons. GPT‑5 looks more like air traffic control: many planes, many runways, constant handoffs, strong rules. That’s less cinematic—and far more useful.
I think that while the models improve, they still are flailing around the same data pools. Bottom scraping is yielding more convincing wrong information in many cases. I'd love for the industry to improve there. We're doing what we can on our end.
Scott Swanson
Founder, Blacksite AI
www.theblacksite.ai