
Measuring the Machines that Kill
A Quantitative Framework for Understanding Value of LLMs in Military Targeting


A note on perspective. I do not write about this topic in a vacuum, as Claude was not only linked to the actions in Iran, but speculation that Claude played some role in the bombing of an elementary school.
As a father of two young children, it’s difficult to put a quantitative abstraction upon a tragic event, but the media conversations about the risks and value of AI in military operations are emotionally charged and uninformed / misinformed.
I have built algorithms for military applications for over fifteen years and working on natural language problems for almost thirteen. I was part of the Project Maven ecosystem from 2018 to 2020. I co-founded and run Legion Intelligence, a defense AI company building secure agentic systems for Department of War (DoW) customers. Legion’s thesis is that the orchestration and governance layer for defense AI is where durable value lives, not in the frontier models alone. That aligns with this essay’s conclusions. The reader should weigh my discussion accordingly.
Everything here draws exclusively from public sources. Where I estimate values, I state the assumptions as illustrative, not empirical. I encourage deeper analysis to be done to further understand the value of new AI models in these critical processes.
One final question I won’t address in this post: what if using Claude (or any modern LLM) actually saves lives? This is the Tesla FSD debate, and I’ll save that for a future post.
Why This Article Exists
On February 28, 2026, a precision munition struck the Shajareh Tayyebeh girls’ elementary school in Minab, Iran, killing at least 168 people, most of them children between seven and twelve. [1] The school sat adjacent to an Islamic Revolutionary Guard Corps (IRGC) naval compound. Multiple independent investigations have concluded the United States was likely responsible. [2] The emerging consensus is that the school, separated from the military compound by a wall since approximately 2016, was struck as part of a precision package against the IRGC facility, likely because the targeting data predated the building’s conversion to a civilian school. [3]
Within days, Reuters reported that Anthropic’s Claude was embedded in Palantir’s Maven Smart System (MSS) and had been used in planning strikes during the Iran campaign. [4] The Pentagon refused to confirm whether AI was involved in selecting the school. [5]
Since then I have taken dozens of calls from reporters, analysts, and people across the defense community. Almost all arrived with the same question: did Claude kill those girls?
I do not have any specific information that has not been reported and verified, but the answer seems much more aligned with outdated information on a target that was on a military installation. The reporting is still coming in as of the time I write this, so I will let the investigation speak for itself.
What I can do is lay out where a large language model (LLM) may actually fits within the Maven Smart System (MSS) architecture, what it plausibly contributed, and where the failure that led to the Minab bombing more likely sits. The children who died deserve at least that much precision in how we talk about what happened.
The Short Version
Maven has been a functioning, combat-tested targeting platform, built years before Claude was added. MSS already used dedicated computer vision (CV) models for imagery, various natural language processing (NLP) models for entity extraction, Palantir’s ontology for data fusion, and structured optimization workflows for prioritization. Claude was layered on top in late 2024, primarily as a natural language interface and unstructured data processing aid. [4] [6]
Two questions get conflated in every conversation about this. First: does the LLM make each individual targeting decision more accurate? Second: does it let the system process more decisions per unit time? The publicly reported value of Maven is overwhelmingly about throughput. Thirty decisions per hour to eighty. An aspiration of a thousand. [9] [13] Without discussing specific workflows that exist in the DoW, I can validate that the use of LLMs as part of many pre-existing workflows drastically increases the throughput.
On the accuracy front, it’s a bit harder to know how and where LLMs incrementally benefit pre-existing methods, so I’ll illustrate estimates that the LLM’s contribution to per-decision accuracy is likely at best 5-8%, with the strongest gains at the Filter and Identify steps. If LLMs are used to orchestrate pre-existing models as steps, e.g. call act as a planner or orchestrator, then it’s much more difficult to say that the LLM outright failed or caused incremental damage or benefit.
The chart below shows the accuracy dimension. Blue bars are the pre-LLM system, with some information coming from public estimates, others are illustrative numbers. Red bars are the LLM increment.
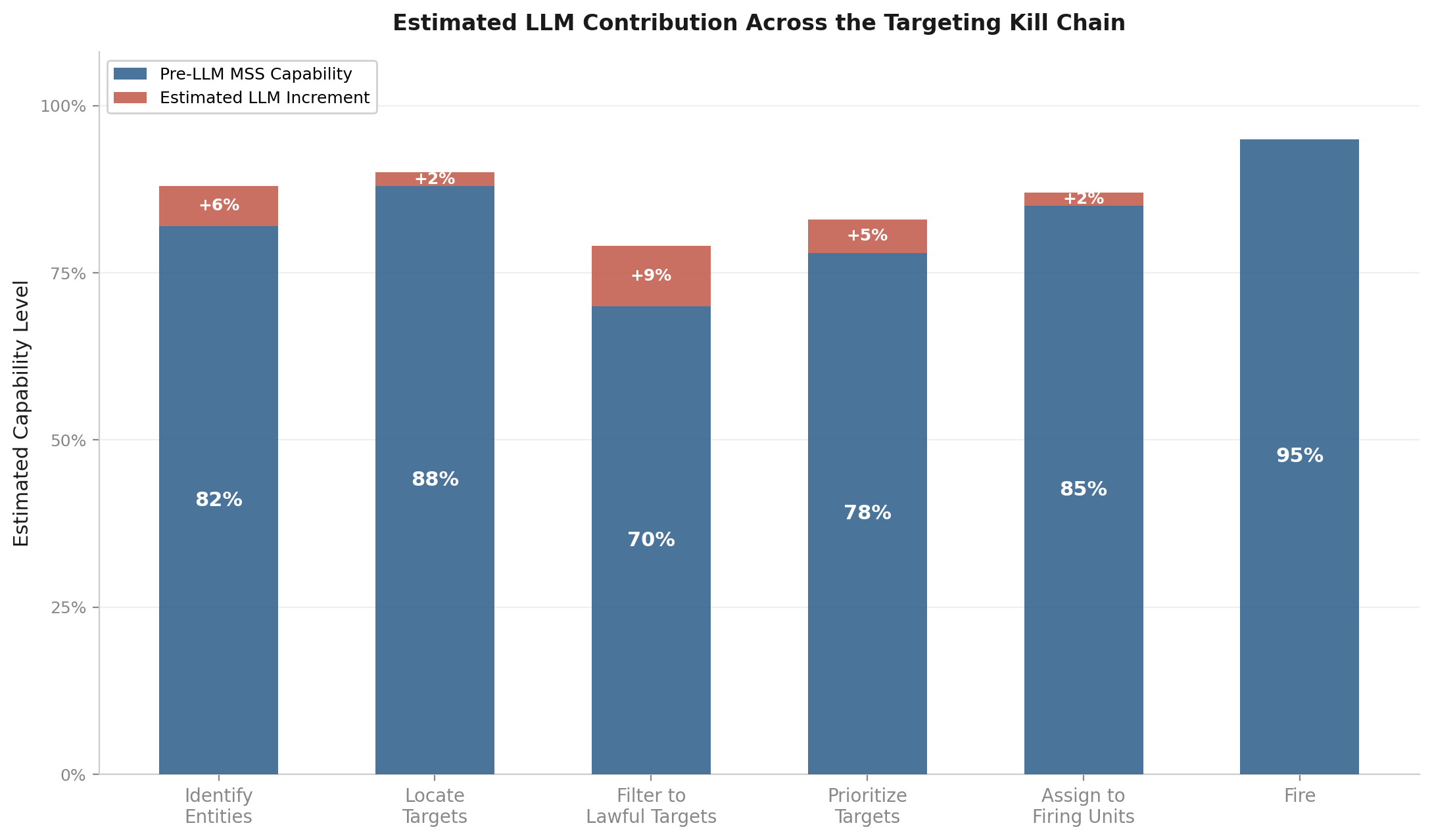
Estimated LLM contribution across the six-step targeting kill chain. Author’s estimates assuming mature pre-LLM systems.
The Targeting Process
The formal joint targeting process is defined in Joint Publication 3-60 (JP 3-60), Joint Targeting, which describes a six-phase cycle: commander’s objectives, target development and prioritization, capabilities analysis, commander’s decision and force assignment, mission planning and execution (including the find, fix, track, target, engage, assess steps), and assessment. [15] The simplified kill chain from Scarlet Dragon exercises collapses this into six functional steps: identify entities of interest, locate them, filter to lawful targets, prioritize, assign to firing units, and fire. As of 2024, Maven could perform four of six. [6]
None of these steps were manual before Claude arrived. Broad Area Search-Targeting (BAS-T) used CV models trained on at least four million labeled military objects to scan satellite and drone imagery. [7] Palantir’s ontology fused signals intelligence (SIGINT), human intelligence (HUMINT), imagery intelligence (IMINT), and open-source intelligence (OSINT) feeds. Maven Target Workbench provided structured workflows for nomination, legal review, and approval. [8] By 2024, targeting timelines had compressed from twelve hours to under a minute, staffing from two thousand to twenty, with a senior targeting officer processing eighty targets per hour versus thirty without Maven. [6] [9]
Most of the commentary treats the introduction of AI into targeting as though it replaced a careless process with a dangerous one. The reality is closer to the opposite. The targeting community spent forty years building legal frameworks, precision guidance, collateral damage estimation (CDE), and review processes specifically to minimize civilian casualties. The targeters I have known are highly disciplined professionals, some even viewed in their communities as artisans, who refuse the easy answer in favor of the precise one and carry the weight of their mistakes personally.
AI was introduced into that already rigorous process. The question is whether it made specific steps marginally better or marginally worse. That question requires understanding the baseline. Most of the people opining about this do not.
How Claude Connects to Maven
Claude integrates through Palantir’s Artificial Intelligence Platform (AIP) via two interfaces: AIP Threads, a natural language chat against the ontology, and AIP Logic, LLM-powered functions that read and write to the ontology. [10] [11] The LLM operates within Palantir’s security model. It sees whatever ontology objects it has been granted access to. It does not run computer vision, synthetic aperture radar (SAR) processing, the fires solution, or weapons-target pairing. Those are separate systems.
Reuters reported replacing Claude would take months, not years. [4] That tells you the depth of integration. Claude sits on top of the system. That does not mean it is not very useful, it is just not the foundation.
Across the Kill Chain
The critical assumption: the pre-LLM system was already good. My experience from the Maven era is that the CV and imagery pipeline was more mature than the NLP components. The estimates below reflect that asymmetry. The following are illustrative values for much of the analysis.
Identify entities. Pre-LLM: roughly 80-85%. LLM increment: 4-7 points. Published named entity recognition (NER) benchmarks show traditional NLP models (Bidirectional Encoder Representations from Transformers, or BERT) tuned for targeting use cases and frontier LLMs are closer than commonly assumed: BERT at F1 88-92% versus Claude at an estimated 87-95% depending on domain and prompting strategy. Claude’s current generation models (Opus 4.6 and Sonnet 4.6) outperform GPT-4o by 5-15% on reasoning benchmarks, meaning the NER figures from GPT-4 benchmarks likely understate Claude’s performance. For standard entity types, Claude and fine-tuned BERT are likely within 1-3 points of each other. Claude edges ahead on complex relational extraction and novel entity types. For object identification in imagery, the accuracy gap is narrower than the speed gap; frontier vision-language models (VLMs) can identify military objects but cannot match dedicated detectors on throughput. Throughput increment: potentially 2x on document-heavy identification.
Locate. Pre-LLM: roughly 85-90%. LLM increment: 1-2 points. Primarily a structured data problem handled by geographic information systems (GIS) and SIGINT processing, but LLMs can reason about spatial relationships described in multi-source intelligence.
Filter to lawful targets. Pre-LLM: roughly 65-75%. The LLM’s strongest case. Filtering requires cross-referencing unstructured rules of engagement (ROE) guidance, legal opinions, and intelligence on civilian presence. LLM increment: 5-10 points. Also where failure is most lethal.
Prioritize. Pre-LLM: roughly 75-80%, assuming a real optimization algorithm. LLM increment: 4-6 points. Frontier LLMs handle multi-criteria ranking well when given clear criteria. The solver guarantees optimality; the LLM approximates it. The LLM’s contribution here is really uncertain without empirical testing, but I’m going to give the LLM the benefit of the doubt in that it adds some contribution, and could see a world where it calls a solver to get specifics then adds value on selecting additional factors based on commanders intent or other.
Assign and fire. Pre-LLM: 85-95%. LLM contribution: effectively zero. Advanced Field Artillery Tactical Data System (AFATDS) and ballistics handle these steps.
Weighted across the chain, the LLM’s total accuracy contribution is probably 5-8%. That is not going to change the outcome of any single decision in most cases, but at the scale of hundreds or thousands of targeting decisions, those percentage points compound, if not in the accuracy, the throughput.
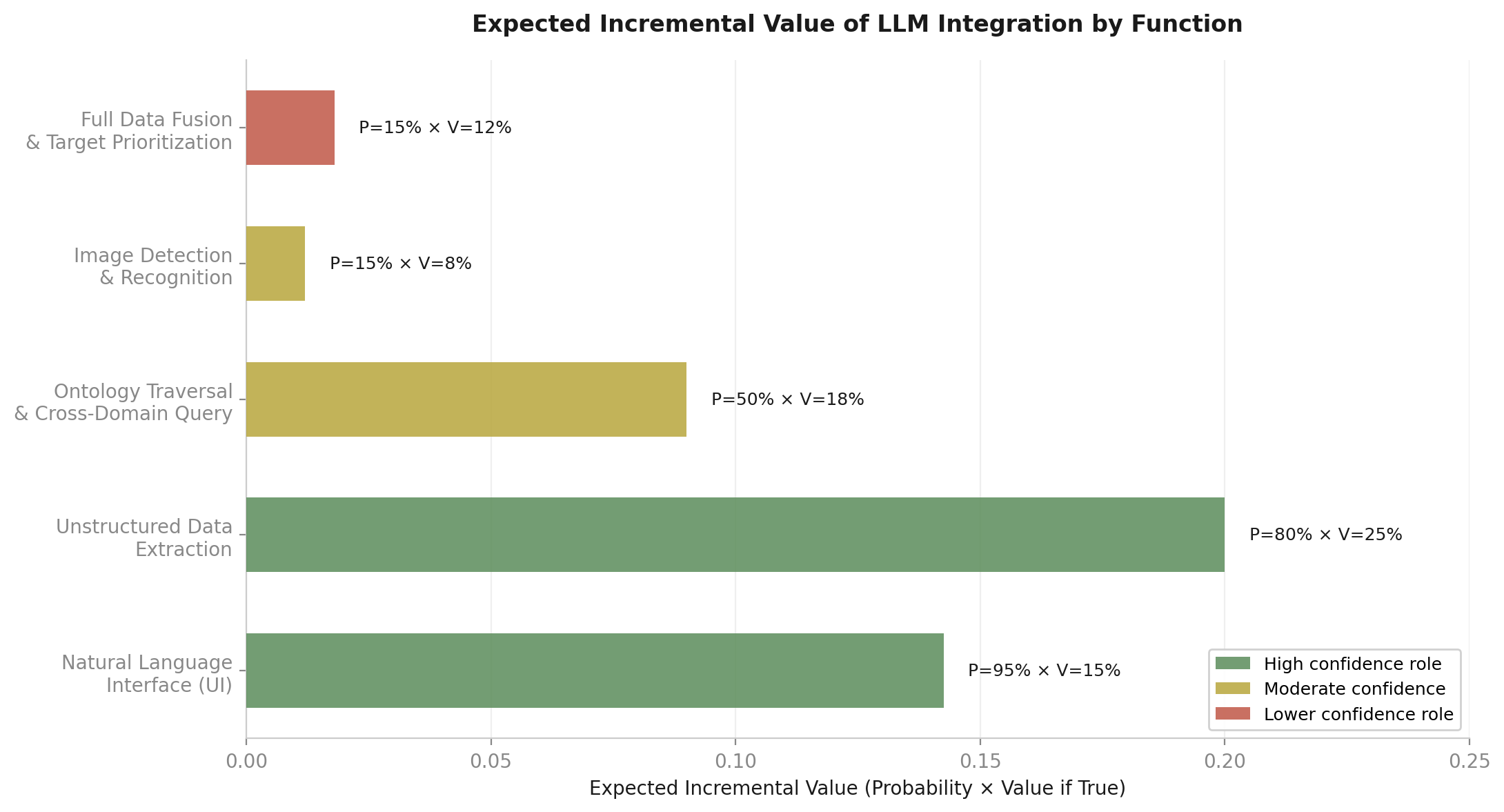
Expected incremental value by function, assuming mature pre-LLM pipeline.
Where LLMs Win and Where They Lose
The benchmarks cited in most commentary reference GPT-4o, which is now two generations behind the frontier. Claude Opus 4.6 and Sonnet 4.6 outperform GPT-4o by 5-15% on reasoning benchmarks and significantly on coding and agentic tasks. [16] No direct benchmarks exist for Claude on military targeting tasks, but I can estimate Claude-specific performance by adjusting published GPT-4o results upward based on the documented performance gap between the two model families across comparable tasks. The following estimates reflect that adjustment.
Object detection: dedicated models still lead, but the gap is narrower than reported. You Only Look Once (YOLO) variants hit 72-85% mean average precision (mAP) on military remote sensing datasets. GPT-4o Vision was benchmarked as “not yet suitable for practical object detection” by AIMultiple, but that was GPT-4o. Claude’s vision capabilities are a generation ahead, with stronger scene understanding and reasoning. For the targeting use case, the question is often “is there a military asset in this image” rather than “draw a bounding box with Intersection over Union (IoU) > 0.5.” For identification rather than localization, Claude is probably within 7-8% of dedicated detectors. The speed gap remains enormous: YOLO runs at 80+ frames per second (FPS); an LLM takes seconds per image.
Entity extraction: nearly equal. Fine-tuned BERT achieves F1 84-92% on domain NER. GPT-4 reached F1 93-94% with structured output prompting. Claude’s language understanding is at least on par with GPT-4 and likely better on context-dependent extraction. For base NER in Maven’s pipeline, Claude and a well-tuned BERT model are probably within 1-3% of each other. On complex relational extraction and novel entity types, Claude likely outperforms BERT.
Unstructured intelligence synthesis: Claude wins. No dedicated model exists for multi-document intelligence synthesis the way YOLO exists for detection. BERT extracts entities. It does not reason across documents. Claude’s 200K-1M token context window, superior reasoning, and ability to handle ambiguity make it a different kind of tool here, not a slightly better version of the same thing. No military benchmark exists for this task.
Commander intent translation: Claude wins. No dedicated model parses complex operational guidance into structured parameters. Traditional NLP maxes out at keyword extraction and template matching. Language-native task, clear Claude advantage.
Target prioritization: solvers are better, but the gap is not as wide as you might think. Dedicated optimization algorithms are provably optimal for constrained problems. But Claude handles multi-criteria reasoning well and can produce sensible priority rankings given clear criteria. The solver guarantees optimality under constraints; Claude approximates it. For well-specified problems with hard constraints, the solver wins. For ambiguous or rapidly evolving situations where the constraints themselves are shifting, Claude’s flexibility has value.
CDE and weapons-target pairing: dedicated systems lead, but Claude contributes context. Blast physics models are deterministic engineering. Assignment algorithms solve matching problems optimally. But Claude can reason about building types, population density, time-of-day patterns, and contextual factors that inform these calculations. Claude is not computing blast radii. It is contributing the contextual inputs that make those computations more accurate.
The mistake both sides make: treating “AI” as one thing. The CV model detecting a tank is a fundamentally different technology from the LLM summarizing an intelligence report. Different architectures, different training data, different failure modes. Arguing about whether “AI” belongs in targeting is like arguing about whether “software” belongs in medicine.
The values below represent estimates. Where published benchmarks exist, I have cited them. Where they do not, I have estimated based on architectural analysis and the documented performance gap between Claude and GPT-4o on comparable tasks.
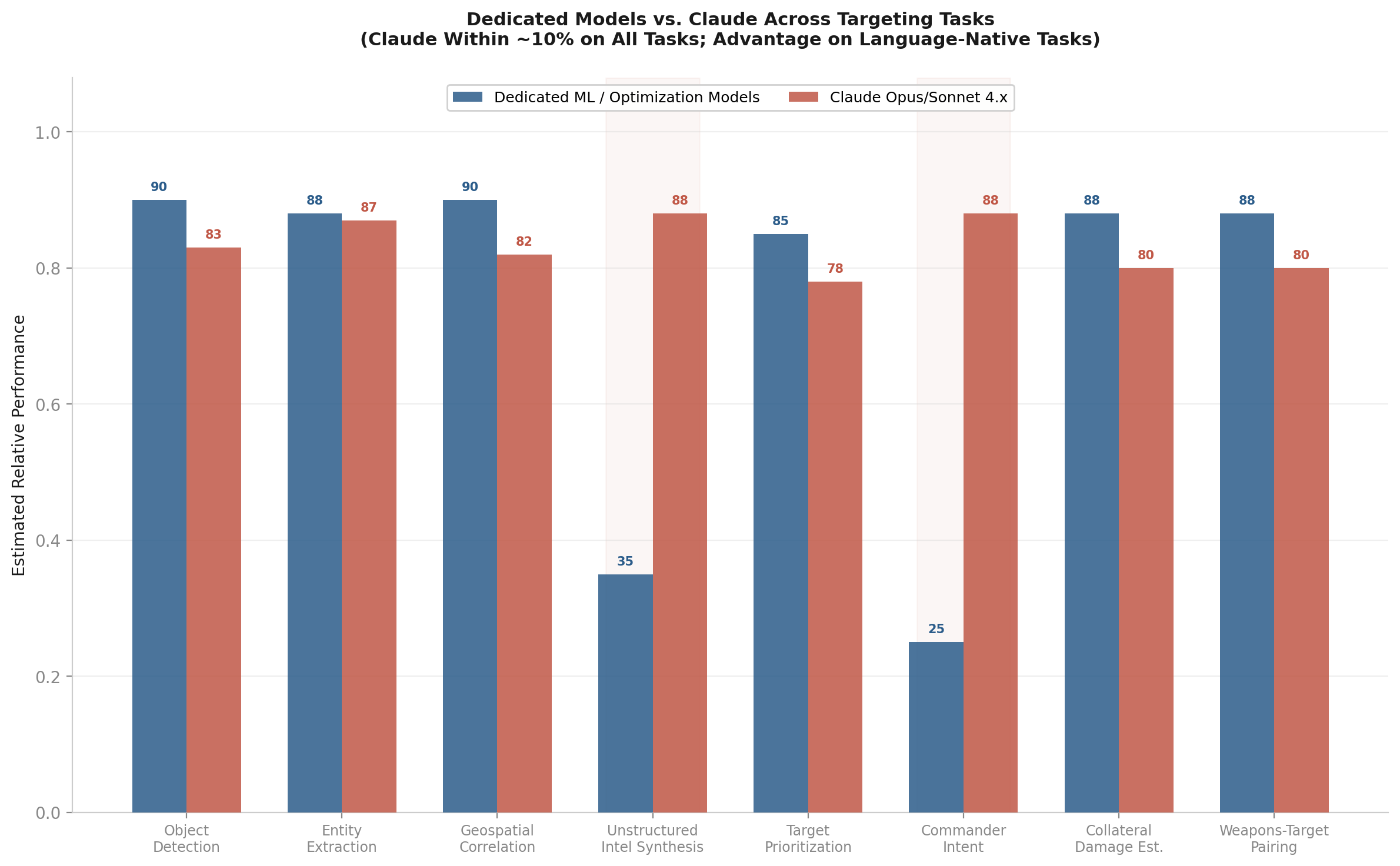
Dedicated models vs. Claude Opus/Sonnet 4.x across targeting tasks.
The Fluency Trap
Now that I have walked through where the LLM contributes and where it does not, I want to name a risk that connects directly to Minab and to the Filter step where I estimated the LLM’s strongest contribution.
A natural language interface gives analysts fast, synthesized understanding. Ask “what do we know about this facility” and get an answer in seconds instead of minutes of dashboard navigation. That compression is real and valuable. But a structured dashboard makes data gaps visible. An empty field is obviously empty. A timestamp marked “2013” is obviously stale. An LLM synthesizing the same data into a confident paragraph can smooth over those gaps. It produces a narrative that feels like understanding but is interpolation across incomplete information. The risk is not fabrication. It is confident synthesis that never flags what it does not know.
The Minab school had been part of an IRGC compound until approximately 2016, when it was walled off and converted to a civilian school. [1] [3] If the targeting system drew from intelligence predating the separation, the building would appear military. A structured database with a “last verified” field would surface the staleness. An LLM might not. It would produce a fluent answer about the facility’s military function without noting the data was a decade old. The European Journal of International Law (EJIL) Talk analysis makes this point: the error is consistent with reliance on outdated intelligence, regardless of whether AI was involved. [12]
I do not know whether this happened at Minab. But this failure mode is known and it is testable. Which brings me to the center of this whole debate.
What We Should Be Benchmarking
The AI industry benchmarks everything except this. Here is what a serious evaluation framework requires:
Data staleness detection. Given a dataset with known stale entries, does the LLM flag the gap or synthesize over it? The most operationally relevant benchmark given Minab.
Intelligence synthesis accuracy. LLM vs. analysts vs. BERT on military-domain text, including degraded, contradictory, and deliberately stale sources.
Legal compliance checking. Miss rate for protected sites, compared to human review under time pressure.
Time-accuracy tradeoff. For a fixed time budget, how does targeting quality compare with and without the LLM?
Error correlation. Are LLM errors correlated across contexts? Correlated errors create systematic bias that reviewers miss because the errors all track in the same direction.
Hallucination under domain stress. With incomplete or contradictory data, how often does the LLM present inference as fact?
Standard machine learning (ML) deployment practice for high-stakes domains. That we do not apply it here is a failure of will.
The Honest Answer
Claude most likely made existing data more accessible, provided meaningful improvement in synthesizing unstructured intelligence, and sped up analyst interaction with the system. The per-decision accuracy improvement could plausibly be in the 5-8%, concentrated at the Filter and Identify steps. The throughput improvement is probably larger.
Claude almost certainly did not perform object detection, geospatial correlation, target prioritization, or weapons-target pairing. If it did, it was hopefully done so given a backdrop of rigorous testing relative to the existing solution, and begs some larger questions about the role of MSS and models within it.
The LLM may have introduced a new failure mode: confident synthesis over incomplete data with a friendly language-based interface. Whether that contributed to Minab is an open question. That the risk exists and nobody is measuring it is not.
168 people are dead, most of them children. The AI companies that benchmark everything from code generation to trivia have published nothing on how their models perform in the workflows where those models help decide who lives and who dies. The commentators who are certain about Claude’s role have never looked at a targeting cycle. Neither approach serves anyone.
The AI industry benchmarks everything. It is past time to benchmark this.
Sources
[1] Wikipedia, “2026 Minab school airstrike.” Walled within IRGC compound 2013, walled off September 2016. 168-180 killed.
[2] CBC News visual investigation, March 2026. Also: NPR, CNN, NYT, Bellingcat.
[3] Al Jazeera, March 3, 2026. School “separated from the military complex... for more than 10 years.”
[4] Reuters via Yahoo Finance, March 2026. MSS “uses prompts and workflows built using Claude code.”
[5] Futurism, March 2026. CENTCOM: “We have nothing for you on this at this time.”
[6] Wikipedia, “Project Maven.” Six-step kill chain; Maven performs four. 80 targets/hour vs. 30.
[7] CW2 Chabrier-Montijo, “XVIII Airborne Corps BAS-T Employment,” US Field Artillery Association.
[8] DefenseScoop, September 12, 2025. Foundry, Gaia, Target Workbench, Maverick, LogX.
[9] Probasco, “Building the Tech Coalition,” CSET Georgetown, August 2024.
[10] Palantir, “AIP Overview.” palantir.com/docs/foundry/aip/overview
[11] Palantir, “AIP Agent Studio” / “AIP Logic.” palantir.com/docs/foundry/agent-studio/overview
[12] EJIL Talk, “AI and International Crimes: Minab School Strike,” March 2026.
[13] Army Times, August 21, 2024. CSET: 1,000 decisions/hour aspiration.
[15] Joint Chiefs of Staff, Joint Publication 3-60, “Joint Targeting,” January 31, 2013 (revised September 28, 2018). Defines the six-phase joint targeting cycle and Find, Fix, Track, Target, Engage, Assess (F2T2EA) execution steps.
[16] Artificial Analysis Intelligence Index, March 2026. Claude Opus 4.6 scores 53; GPT-4o significantly lower. Claude Sonnet 4.6 scores 52. Claude 4.x generation outperforms GPT-4o by 5-15% on reasoning tasks. artificialanalysis.ai
[17] DefenseScoop, September 10, 2025. Contract ceiling ~$1.3B through 2029.